Influence of First Connections for a New Employee on Growth and Retention
Social network matter in engaging a new member in a community. Are there patterns in initial connections in the new company that influence future retention in the company? How does a new employee in a company network or connect with other employees of the company? Is there any similarity in the company network of a new employee?
Despite the importance of these questions, there is a little understanding on how the ego-network (connections of an individual and network of connections between them) of a new member of a community evolves within the community. Recently we analyzed LinkedIn’s data and published a detailed study to answer these questions at World Wide Web (WWW) Conference:
Influence of First Steps in a Community on Ego-Network: Growth, Diversity, and Engagement
In this post I will discuss some of the highlights of the paper including growth of network in a new company, diversity of network and retention of new employee over time.
We use top 500 companies in LinkedIn (by average degree), which includes more than 1 million members and more than 100 thousands new employees in 2013. To our knowledge, this is the largest analysis on company network and employees behavior.
Connecting with senior and large network people initially results in longer retention
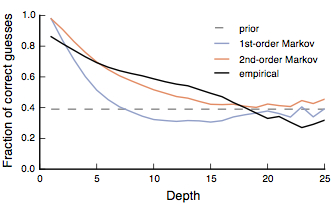
First, we looked into whether there is any relationship between initial connections after joining a company and retention in the company. We looked at the network size and seniority of first ten connections for a new employee inside a company. We checked whether the new employees work for the same company after 1.5 years. We found that if initial connections are more senior and have larger network then the new employee is less likely to leave the company early.

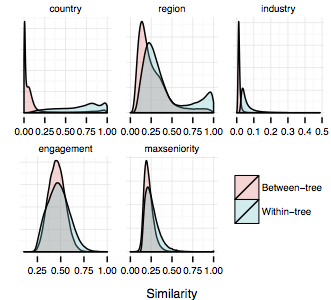
More diverse your initial friends network implies more diverse and large network for you over time
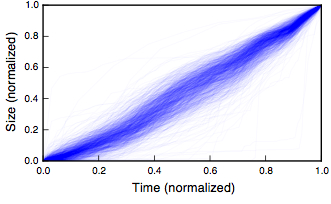
Second, is there any relation between the network status of initial connections of new employee and their future network status? We computed average degree and functional group diversity in their first 10 connections ego-network. After data analysis, we obtained the final degree and functional group diversity in the final ego-network after 1.5 years. We found that more diverse your initial connections network implies more diverse and large network for you over time.

Network growth through triadic-closure led by high-degree people
Finally we analyzed the growth of network for new employees. We found that new employees grow their network through triad-closing propagation led by high-degree people.

Figure: Larger Weiner index implies that the real network is more viral in the triadic-closure propagation than a random network.
For more details check out our paper:
Influence of First Steps in a Community on Ego-Network: Growth, Diversity, and Engagement, Atef Chaudhury, Myunghwan Kim, and Mitul Tiwari. In the Proceedings of the 25th International Conference Companion on World Wide Web (WWW), April 2016.