Search plays an important role in online social networks such as LinkedIn as it provides an essential mechanism for discovering members and content on the network. Related search recommendation is one way for improving members’ search experience in finding relevant results. We recently wrote a paper on Metaphor, the related search recommendation system at LinkedIn [1], which is going to appear in proceedings of the
21st Internationl Conference on Information and Knowledge Management (CIKM), 2012. I am also giving a presentation on related search at LinkedIn at
SIGIR 2012 conference, the premier information retrieval gathering. I am happy to discuss some of the interesting findings from our paper here.
Design
Metaphor builds on a number of signals and filters that capture several dimensions of relatedness in search activity.
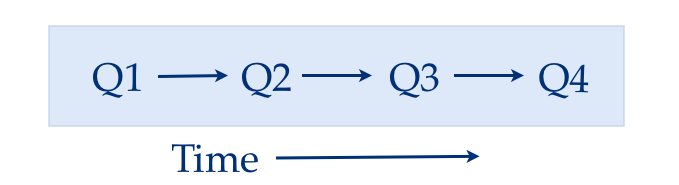
Correlation based on time: The first signal is based on collaborative filtering by analyzing searches done in the same sessions, that is, searches correlated by time are considered related. For example, members search for “Hadoop” and “big data” in succession then we can say those two queries are related .One challenge is to deal with popular queries like “Obama” by damping popular queries by a TF-IDF measure.
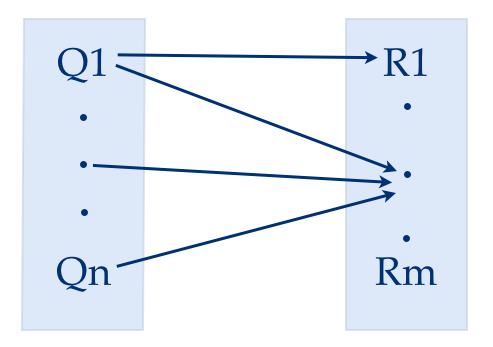
Correlation based on clicks: The second signal is based on query-result clicks, that is, search queries that result in clicking the same result. For example, search results for queries “Hadoop” and “MapReduce” have a common result that is clicked often by members, then we can say those two queries are related. LinkedIn’s personalized search results brings added richness to the queries related by this signal.

Correlation based on term overlap: The third signal is based on overlapping terms present in the queries. For example, queries “Jeff LinkedIn” and “LinkedIn CEO” has a common term “LinkedIn, and we can say those two queries are related. One challenge here is identifying the importance of each term. For example, for search query “iOS engineer”, and two candidate queries “iOS developer” and “mechanical engineer”, the overlapping term query “iOS developer” is more important, although there is only one term is common between the search query and the candidate queries. We address this challenge by weighing importance of terms by a variant of TF-IDF measure.
Length bias: The fourth and the final signal is based on the number of terms in the search query and the candidate related queries. While working on this project we arrived at an interesting insight that members tend to click on suggested queries that are one term longer than their initial query, which corresponds to refining the initial query. For example, LinkedIn members tend to search for “Hadoop developer” after searching for “Hadoop”. We developed a statistical biasing model to give more importance to a longer query recommendation and use it for final query ranking.
Implementation
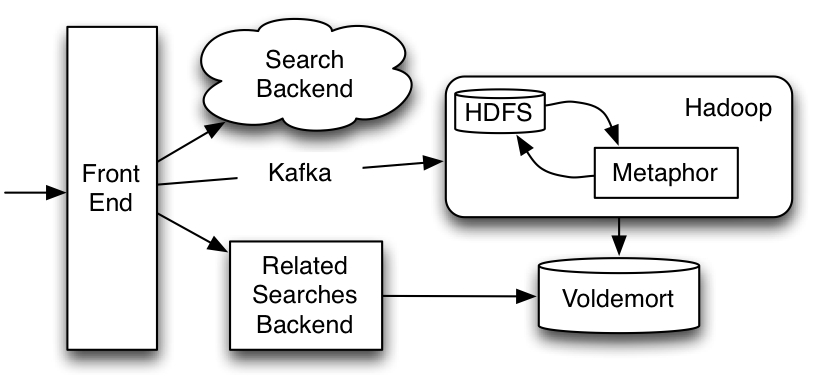
Metaphor, our related search recommendation engine runs on Hadoop. The query logs and activity tracking data is aggregated from the production systems using Kafka, a publish-subscribe streaming system for event collection and distribution. Metaphor consists of several map-reduce jobs implemented in Hadoop Java and Pig, a scripting language on top of Hadoop. Azkaban, a Hadoop workflow management tool, is used for managing Metaphor’s more than 50 map-reduce jobs. The final recommendations are stored in Voldemort, a key-value store system, and served in production from Vodemort store.
We evaluated Metaphor in various ways using traditional Precision-Recall measure as well as online A/B testing. Check out our paper [1] for more details.
References
Metaphor: a system for related search recommendations, Azarias Reda, Yubin Park, Mitul Tiwari, Christian Posse, and Sam Shah. In Proceedings of the 21st International Conference on Information and Knowledge Management (CIKM), October 2012 (to appear).